Upload File to Github From Virtual Mathin
How to Upload Large Prototype Datasets into Colab from Github, Kaggle and Local Motorcar
Learn how to upload and access large datasets on a Google Colab Jupyter notebook for training deep-learning models
Google Colab is a free Jupyter notebook surround from Google whose runtime is hosted on virtual machines on the cloud.
With Colab, you need not worry about your computer's memory capacity or Python package installations. You go gratuitous GPU and TPU runtimes, and the notebook comes pre-installed with machine and deep-learning modules such as Scikit-acquire and Tensorflow. That beingness said, all projects require a dataset and if you are non using Tensorflow's inbuilt datasets or Colab'due south sample datasets, you lot volition demand to follow some simple steps to accept admission to this data.
Understanding Colab's file system
The Colab notebooks you create are saved in your Google drive folder. Yet, during runtime (when a notebook is active) it gets assigned a Linux-based file system from the cloud with either a CPU, GPU, or TPU processor, as per your preferences. Yous can view a notebook's current working directory by clicking on the folder (rectangular) icon on the left of the notebook.
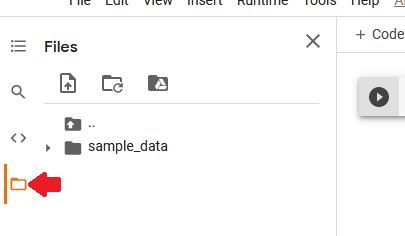
Colab provides a sample-data folder with datasets that you tin can play around with, or upload your own datasets using the upload icon (side by side to 'search' icon). Annotation that in one case the runtime is disconnected, you lose access to the virtual file arrangement and all the uploaded data is deleted. The notebook file, however, is saved on Google bulldoze.
The folder icon with 2 dots higher up sample_data folder reveals the other core directories in Colab's file system such equally /root, /home, and /tmp.
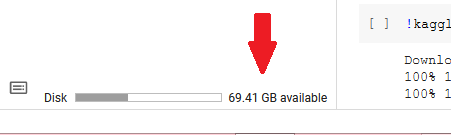
You tin can view your allocated disk space on the lesser-left corner of the Files pane.
In this tutorial, we will explore ways to upload image datasets into Colab's file organisation from three mediums so they are accessible by the notebook for modeling. I chose to save the uploaded files in /tmp , only you lot tin besides save them in the electric current working directory. Kaggle'south Dogs vs Cats dataset will be used for demonstration.
i. Upload Information from a website such a Github
To download information from a website direct into Colab, y'all need a URL (a web-folio accost link) that points directly to the zip folder.
- Download from Github
Github is a platform where developers host their code and work together on projects. The projects are stored in repositories, and past default, a repository is public pregnant anyone tin can view or download the contents into their local machine and outset working on information technology.
Commencement step is to search for a repository that contains the dataset. Here is a Github repo by laxmimerit containing the Cats vs Dogs 25,000 training and test images in their respective folders.
To use this process, you lot must take a gratuitous Github account and exist already logged in.
Navigate to the Github repo containing the dataset. On the repo's homepage , locate the dark-green 'Lawmaking' button.
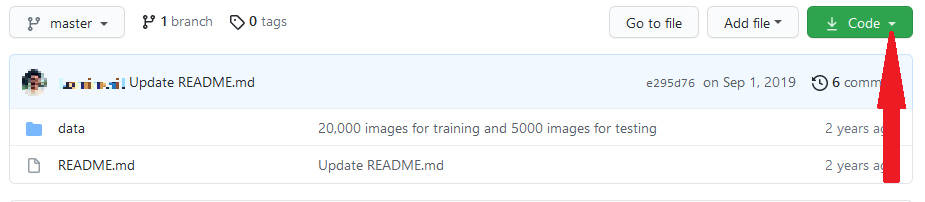
Click on the arrow to the right of this 'code' button. This will reveal a drop-down list.
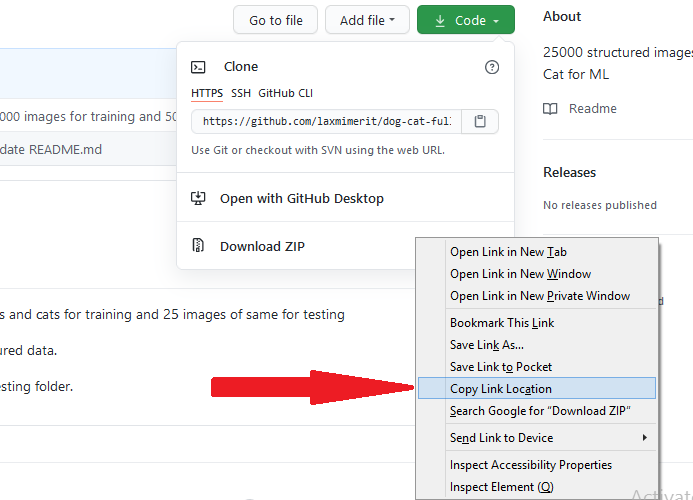
Right-click on 'download zip' and click the 'copy link location'. Note: this will download all the files in the repo, merely we volition sift out unwanted files when nosotros extract the contents on Google Colab.
Navigate to Google Colab, open a new notebook, blazon and run the two lines of lawmaking below to import the inbuilt python libraries nosotros need.
The lawmaking beneath is where we paste the link (second line). This unabridged code block downloads the file, unzips information technology, and extracts and the contents into the /tmp folder.
The wget Unix command: wget <link> downloads and saves web content into the electric current working directory (Notice the ! because this is a shell command meant to be executed by the system command-line. Also, the link must end with .zip). In the lawmaking above, we provide (optional) a download directory (/tmp), and desired name of the downloaded null file (cats-and-dogs.naught). We utilise — -no-check-certificate to ignore SSL certificate error which might occur on websites with an expired SSL certificate.
Now that our cipher contents have been extracted into /tmp binder, we demand the path of the dataset relative to the Jupyter notebook nosotros are working on. As per the image below, click on binder icon (arrow i) then file organization (2) to reveal all the folders of the virtual system.
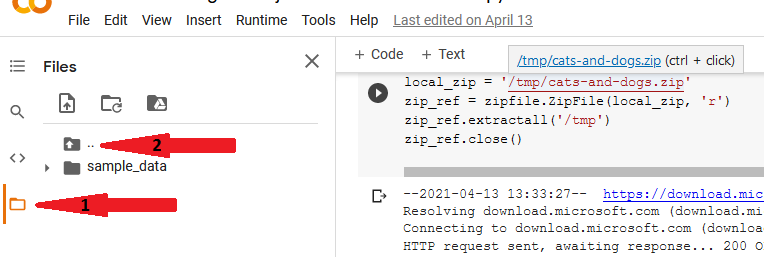
Curlicue down and locate the /tmp folder within which all our image folders are.
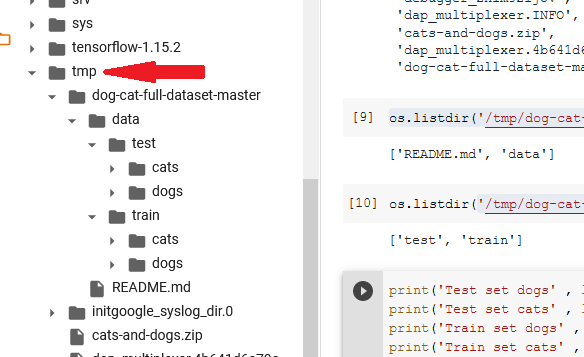
Y'all can use os.listdir(path) to return a python list of the folder contents which you can salve in a variable for use in modeling. The code below shows the number of images of cats and dogs in the train and exam folders.
- Upload data from other websites
Other websites similar the popular UCI repository are handy for loading datasets for automobile learning. A unproblematic Google search led me to this web page from Microsoft where you tin get the download link for the Dogs vs Cats dataset.
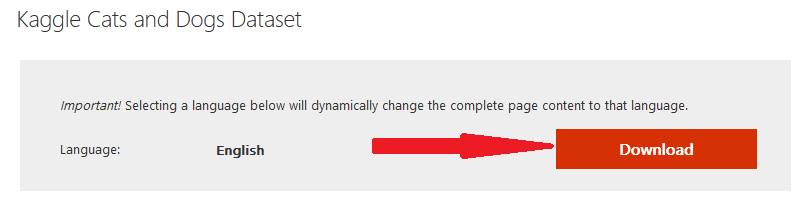
When you click on the 'Download' button, 'Cancel' the pop-up message that asks whether to 'open' or 'save' the file.
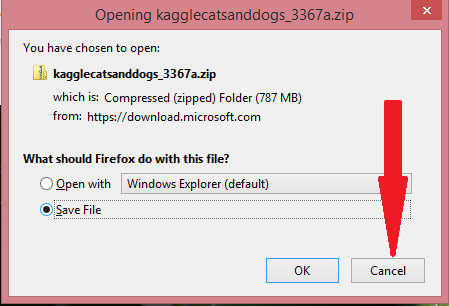
The webpage now shows a link 'click here to download manually'. Correct click on information technology and then click on 'Copy link location'.
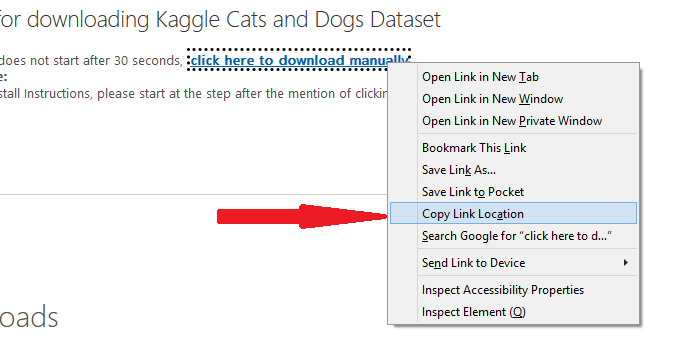
Open a new Google Colab Notebook and follow the same steps described with the Github link higher up.
2. Upload Data from your local auto to Google Drive and then to Colab
If the data gear up is saved on your local machine, Google Colab (which runs on a split up virtual machine on the deject) will not have direct access to information technology. Nosotros will therefore need to first upload it into Google Drive then load it into Colab's runtime when edifice the model.
Note: if the dataset is modest (such as a .csv file) you can upload it directly from the local machine into Colab'due south file arrangement during runtime. However, our Prototype dataset is large (543 Mb) and it took me 14 minutes to upload the naught file to Google Drive. One time on the Drive, I tin can at present open a Colab notebook and load it into runtime which will take roughly a minute (demonstrated in code below). However, If you were to upload information technology straight to Colab's file system, presume information technology will take 14 minutes to upload, and one time the runtime is asunder you have to upload information technology once more for the same corporeality of time.
Before uploading the dataset into Google Bulldoze, information technology is recommended that information technology exist a unmarried goose egg file (or similar annal) because the Drive has to assign private IDs and attributes to every file which may take a long time.
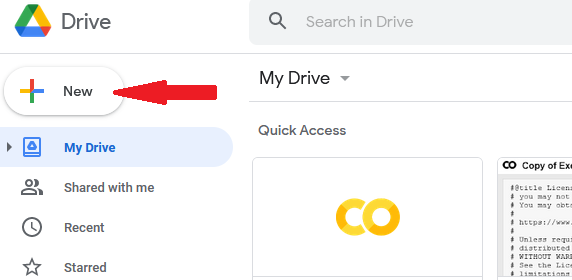
Once the dataset is saved in your local motorcar (I downloaded it from here on Kaggle), open your Google bulldoze and click the 'New' button on the top-left. From the drop-down list, click on 'File Upload' and browse to the cipher file on your system then 'Open' it.
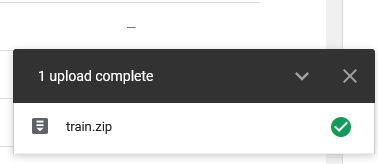
On the bottom right will appear a progress bar indicating the upload process to completion.
At present open up a new Colab notebook. The first block of code mounts the Google drive so that it's accessible to Colab's file organisation.
Colab will provide a Link to authorize its access to your Google account's Drive.

Click on this link (arrow i above), choose your email address, and at the lesser click on 'Let'. Next, copy the code from the pop-up and paste it in Colab's textbox (pointer two) and finally this message will be displayed: Mounted at /content/drive .
At present when we expect at the files at the left of the screen, we come across the mounted drive.
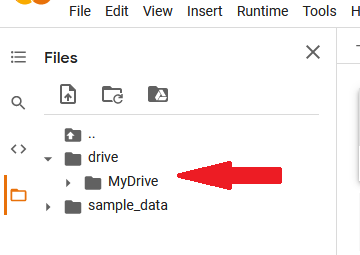
Next is to read the dataset into Colab's file system. Nosotros volition unzip the folder and extract its contents into the /tmp folder using the lawmaking below.
Now you lot tin can view the path to Colab'southward /tmp/railroad train folder from the file system.
Use os.listdir(path) method to render a list of the contents in the data binder. The code beneath returns the size (number of images) in train folder.
iii. Upload a dataset from Kaggle
Kaggle is a website where information scientists and car learning practitioners interact, learn, compete and share code. Information technology offers a public data platform and has thousands of public datasets either from by or ongoing Kaggle competitions, or uploaded by community members who wish to share their datasets.
The Cats vs dogs dataset was used in a motorcar learning competition on Kaggle in 2013. Nosotros volition download this dataset straight from Kaggle into the Colab's filesystem. The following steps are essential considering yous require authentication and permissions to download datasets from Kaggle.
Step One: Download the configuration file from Kaggle
Kaggle provides a mode to interact with its API. Yous demand a free Kaggle account and be signed in.
Click on your avatar on the acme right of your homepage. Choose 'Account' from the drop-downwards card.
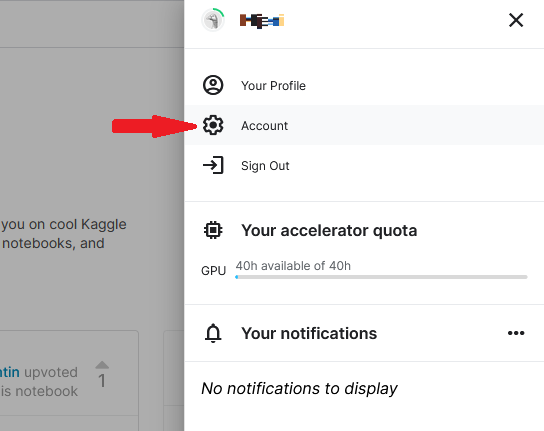
On the 'Account' folio, Scroll down to the 'API' department and click on 'Create New API Token'.
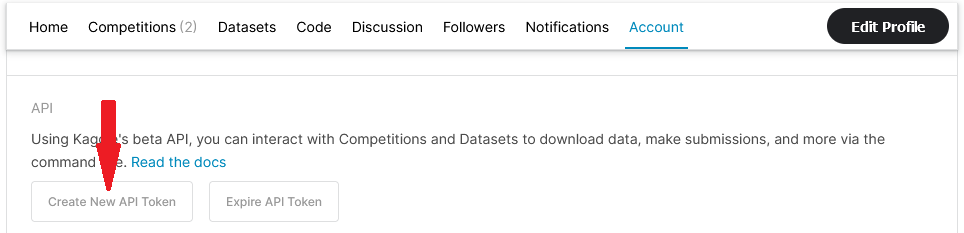
You volition be prompted to download a file, kaggle.json. Choose to salvage information technology to your local motorcar. This is the configuration file with your credentials that you lot will use to directly access Kaggle datasets from Colab.
Note: Your credentials on this file expire later on a few days and you will get a 401: Unauthorised error in the Colab notebook when attempting to download datasets. Delete the old kaggle.json file and come back to this stride.
Step Two: Upload the configuration file to a Colab notebook
Now with a fresh kaggle.json file, you can leave it on your local machine (step Two a), or relieve (upload) information technology on Google Drive (step Two b).
Stride Ii (a) : If the file remains on your local machine, you tin upload it into Colab's electric current working directory using the upload icon, or using Colab's files.upload(). This option is simpler if yous utilize the aforementioned reckoner for your projects. If using code (not upload icon), run the code below in a new notebook, browse to the downloaded kaggle.json file, and 'Open' it.

The file will appear in your working directory.
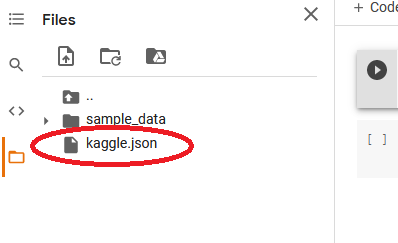
Footstep 2 (b) : The second option is to save (upload) the kaggle.json file to Google Bulldoze, open a new Colab notebook and follow the simple steps of mounting the Bulldoze to Colab's virtual system (demonstrated below). With this second option, you can run the notebook from any automobile since both Google bulldoze and Colab are hosted on the cloud.
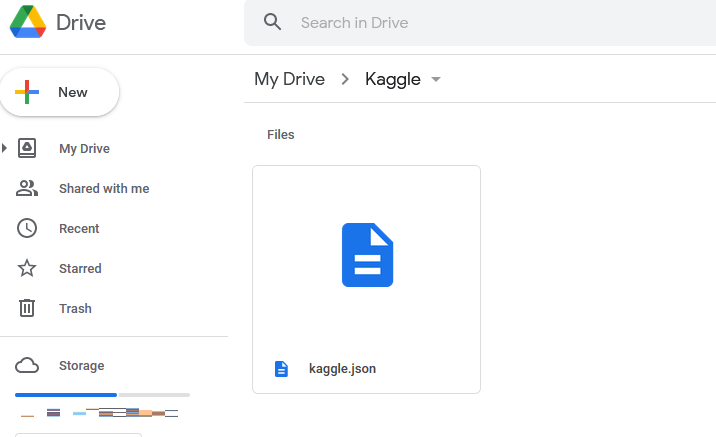
On Google Drive, create a new folder and call it Kaggle. Open this folder by double-clicking on information technology and upload kaggle.json file.
Next, open a Colab notebook and run the lawmaking beneath to mount the Drive onto Colab's file system.
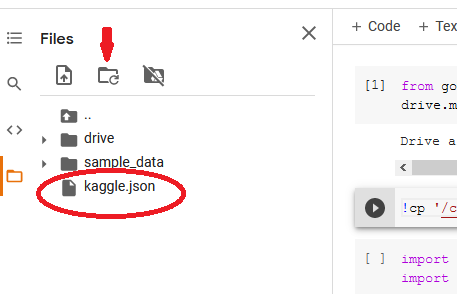
Once this is successful, run the lawmaking below to copy kaggle.json from the Bulldoze to our current working directory which is /content ( !pwd returns the current directory).
Refresh the files section and locate kaggle.json in the current directory.
Step 3: Point the os environment to the location of the config file
Now, we will employ the bone.environ method to show the location of kaggle.json file that contains the authentication details. Remember to import the files needed for this.
Step four: Copy the dataset's API control from Kaggle
Every dataset on Kaggle has a corresponding API control that you can run on a command line to download it. Note: If the dataset is for a contest, go to that contest's page and 'read and take the rules' that enable you to download the data and brand submissions, otherwise you will get a 403-forbidden error on Colab.
For our Dogs vs Cats dataset, open the contest page and click on the 'Data' tab. Whorl down and locate the API command (highlighted in black below).
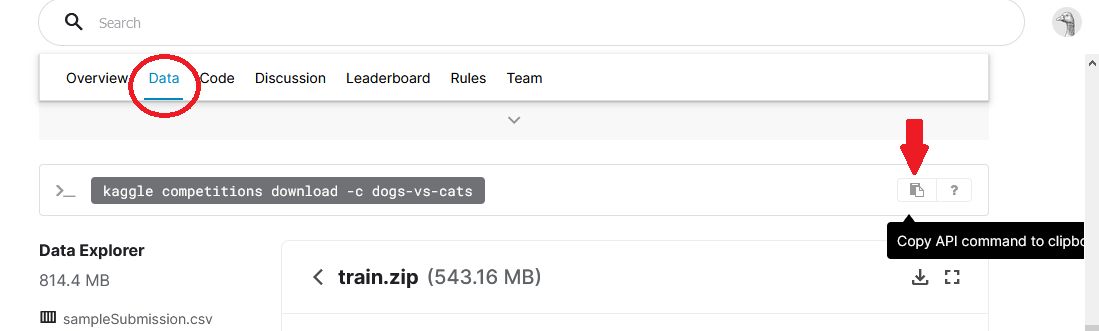
For other datasets (not competitions), click on the 3 dots next to the 'New notebook' button and so on 'Copy API control'.
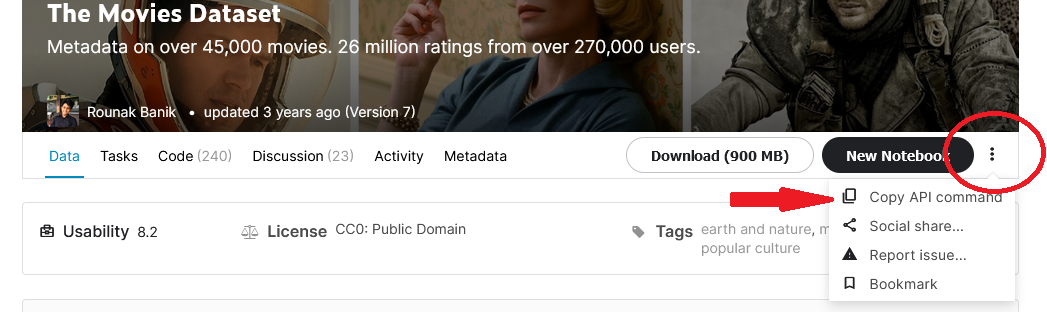
Step 5: Run this API control on Colab to download the data
Back to our Colab notebook, paste this API command to a new block. Retrieve to include the ! symbol that tells python that this is a command-line script.
If all works well, confirmation of the download will be displayed. I got the results beneath.

Now from the Files pane on the left, yous can come across all the folders that were downloaded.
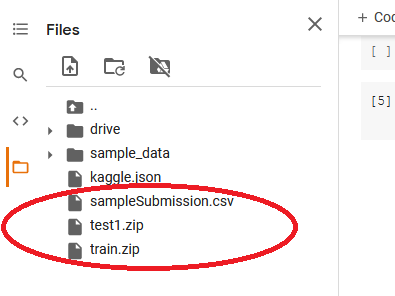
Footstep half-dozen: Extract the files
At present we can extract the files in train.zip file and save them in /tmp (or the current directory /content).
Run the code below to return the number of files in the extracted binder.
Decision
In this tutorial, we explored how to upload an image dataset into Colab'south file organisation from websites such equally Github, Kaggle, and from your local machine. Now that you have the data in storage, you can railroad train a deep learning model such as CNN and attempt to correctly classify new images. For bigger image datasets, this article presents alternatives. Thanks for making information technology to the end. Wish y'all the best in your deep learning journeying.
Source: https://towardsdatascience.com/an-informative-colab-guide-to-load-image-datasets-from-github-kaggle-and-local-machine-75cae89ffa1e
0 Response to "Upload File to Github From Virtual Mathin"
Post a Comment